 什么是vLLM?
什么是vLLM?
随着最近大规模语言模型(以下简称LLM)的流行,从ChatGPT开始,开发了一个触手可及的运行LLM的环境。
最基本的可能就是Hugging Face 的Transformer 了。 其他示例包括易于使用的llama.cpp 、旨在加速推理的NVIDIA 的TensorRT-LLM和SGLang 。 vLLM就是其中之一,是LLM的所谓“推理引擎 ”。
vLLM提供了一种加速LLM推理处理的机制,我们特别关注提高吞吐量(单位时间的令牌生成速度)。 有一些据说速度比较快,但是vLLM的信息量很大,而且很容易理解,所以这篇文章我们主要关注vLLM。
加速的具体机制在官方解释和各种文章中都有介绍,但我感觉遵循具体实现的文章很少。
当您阅读本文时,您的主要目标是了解以下几点:
- 在线和离线推理之间没有性能差异。
- 调度流程
- 批量推理和内存块管理的实际状态
请注意,vLLM 由于开发而经常发生变化,因此如果您关注最新的分支,您正在查看的部分可能会在下周发生变化。 引用的代码是在10月至12月初检查的,因此 可能与目前最新的代码有所不同。
 必备知识
必备知识
从头开始解释LLM如何运作将需要很长时间,因此我们将从一定程度的知识开始。
下面的文章整理得很好,可以给你一个想法,所以请阅读。
- 参考
- vLLM:通过 PagedAttention 轻松、快速且廉价地提供 LLM 服务:官方博客
- 快速了解 vLLM 的工作原理:基于上述的解释
您所需要的就是关注
不用说,这是一篇著名的论文(arXiv链接)。遵循LLM的推理过程需要一定程度的理解。
粗略地讲,你可以认为它是输入上一个推理结果来获得下一个推理结果。
分页关注
Paged Attention 是 vLLM 的功能之一,是一种执行类似于操作系统内存管理的分页式 VRAM 管理的机制。 这样可以有效利用有限的 VRAM 和速度。
相关地,还请理解KV现金这个术语。
连续配料
由于批处理,vLLM 通常被描述为快速高效。 然而,即使它简单地称为批处理,了解批处理的位置和内容也很重要。
推理本身是批量的,还是批量接受请求? vLLM 两者兼而有之,并使用称为“连续批处理”的策略进行批量推理。
这意味着每次 LLM 推理处理的结果获得下一个令牌时,它都会检查当时可以分批处理的请求,并同时处理尽可能多的请求。
因此,同时处理多个请求而不是单个请求时最有效。
 vLLM开发安装(仅限Python代码开发)
vLLM开发安装(仅限Python代码开发)
为了在运行 vLLM 时读取代码,请执行最小的开发安装。
如果只是想运行pip install vllm 是没有问题的 ,但是考虑到代码改动, 我们会基于官方的Build from source Python-only构建(不编译)进行工作。
使用的 GPU 是 NVIDIA GeForce RTX 4070 Ti。 请注意,可能存在执行环境依赖性。
安装轮子
首先,获取一个Wheel来运行vLLM的部分(不包括C/C++/CUDA部分)。我使用uv来管理python,所以我使用以下命令执行它。
uv pip 安装 https://vllm-wheels.s3.us-west-2.amazonaws.com/nightly/vllm-1 0 .dev-cp38-abi3- manylinux1_x86_64.whl。
然而,我突然就迷上了这里。
目前(2024年11月18日),官方声明称版本名称已固定“以使URL唯一”,如下所示。
请注意,wheel 是使用 Python 3.8 ABI 构建的(有关 ABI 的更多详细信息,请参阅 PEP 425),因此它们与 Python 3.8 及更高版本兼容。wheel 文件名中的版本字符串 (1.0.0.dev) 只是一个占位符。轮子的实际版本包含在轮子元数据中,尽管我们不再支持 Python 3.8(因为 PyTorch 2.5 不再支持)。 Python 3.8),轮子仍然使用 Python 3.8 ABI 构建,以保持与以前相同的轮子名称。
但是,这样一来,包依赖关系将无法正确解决,如果您使用认真解决依赖关系的包管理器,您将收到以下错误。使用原始 pip 时它工作得很好,但这已被报告为 pip 中的一个重大错误。
错误:安装失败:vllm-1 .dev0 - cp38 -abi3-manylinux1_x86_64.whl (vllm == 1 . 0 . 0 .dev0 (来自 https: //vllm-wheels.s3.us-west- 2.amazonaws.com/nightly/vllm-1.0.0 .dev-cp38-abi3-manylinux1_x86_64.whl ) )原因:Wheel版本与 文件名 不匹配:0 .dev155 + gf3a507f1.d20241010 !
- 参见uv pip install failes for wheel URLs with placeholder · Issue #8082 · astral-sh/uv · GitHub
- 参见[Bug]: 1.0.0.dev placeholder doesn't work with `uv pip install` · Issue #9244 · vllm-project/vllm · GitHub
所以你pip install 必须使用常规的来遵循官方教程。
uv venv 如果您创建的 venv 没有 pip,则需要采取一些操作,例如将其安装在系统 python 上,或者将 pip 添加到 venv 并运行它(uv add pip 等等) 。pip install 这次我将pip添加到venv中并执行。
克隆存储库
按照公式并运行以下命令:
git 克隆 GitHub - vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs cd vllm python python_only_dev.py
执行时,它将虚拟环境中扩展的包的二进制文件复制到克隆的 vllm 目录中,并将克隆的目录符号链接到虚拟环境。
另外,-q 如果将脚本与脚本一起使用,还可以恢复复制的内容。
启动确认
至此,开发环境已经准备就绪。
让我们开始吧。 当前(2024/11/18)启动命令使用快速入门中列出的以下命令。
vllm 服务 Qwen/Qwen2.5-1.5B-指令
它已经开始了。
信息 11-18 20:44:07 api_server.py:592 ] vLLM API服务器版本0.6.4.post2.dev25 + g01aae1cc INFO 11-18 20:44:07 api_server.py:593 ] args: 命名空间( subparser = ’ serve ’ , model_tag = ’ Qwen/Qwen2.5-1.5B-Instruct ’ , … (省略) … INFO :已启动服务器进程[ 169392 ] 信息:正在等待应用程序启动。 信息:应用程序启动完成。 信息:Uvicorn 在 http:// 0 .0:8000 上运行(按CTRL + C退出)。
兼容 OpenAI 的聊天完成 API 也可以正常运行。
$curl http://localhost:8000/v1/completions \ -H " Content-Type: application/json " \ -d ’ { “model”: “Qwen/Qwen2.5-1.5B-Instruct”, “prompt” : “旧金山是一个”, “max_tokens”: 7, “温度”: 0 } ’ { “ id ”:“ cmpl-f80bb25d622b4af5bc41c5e5b425e16a ”,“对象”:“ text_completion ”,“创建”:1731931161,“模型”:“ Qwen/Qwen2.5-1.5B-Instruct ”,“选择”:[ { “索引" :0, " text " : “所在州的城市加利福尼亚州,”," logprobs “:null,” finish_reason “:” length “,” stop_reason “:null,” prompt_logprobs “:null } ],” usage ":{ " prompt_tokens “:4,” total_tokens “:11,” completion_tokens “:7,” prompt_tokens_details “:null }}
Python代码的修改
最后,通过修改存储库中的代码来检查代码更改是否实际应用。
如果您查看 vllm 命令的作用,它只会执行导入的内容,from vllm.scripts import main 如以下代码所示。main()
-- 编码:utf-8 -- import re import sys from vllm.scripts import main if name == ‘main’ : sys.argv[ 0 ] = re.sub( r’(-script.pyw|.exe)?$’ , ‘’ , sys.argv[ 0 ]) 系统退出(主())
要确认更改,请尝试main() 在内部print() 添加。
diff --git a/vllm/scripts.py b/vllm/scripts.py 索引 a51c21cf…eeffebb3 100644 — a/vllm/scripts.py +++ b/vllm/scripts.py @@ -141,6 +141,7 @@ def env_setup(): def main(): + print(“已修改!!!”) 环境设置() 解析器=FlexibleArgumentParser(描述=“vLLM CLI”)
确实是被展示出来了。它工作正常,没有任何问题。
$ vllm 服务 Qwen/Qwen2.5-1.5B-指令 修改的!!! 信息 11-18 21:09:08 api_server.py:592 ] vLLM API服务器版本0.6.4.post2.dev25 + g01aae1cc … (省略) …
如果继续修改代码,就可以轻松修改为vLLM。
推荐使用调试器读取 OSS 代码
世人如何进行OSS代码读取?
当然,如果你想要遵循特定的流程,那么 grep 并搜索相关词会更快。 如果不是太复杂,找到一个切入点并从那里开始工作可能会有所帮助。
然而,就我个人而言,当我阅读代码时,如果我实际尝试一下,我会更容易理解它。 幸运的是,Python 可以使用 VSCode 轻松调试,所以我用它来继续阅读。 (如果您只想调试库的内部,您可以将其设置justMyCode 为false ,但这次我们已经可以实际修改代码以预期将来的修改。)
因此,我建议使用调试器在关键点进行中断,因为这样可以让你在运行时看到变量中实际存储的内容,更容易理解。
 vLLM 软件架构
vLLM 软件架构
现在,我们来看看正题,vLLM 代码。
官方文档非常全面,建议您先参考一下。 该文档有稳定的最新版本,因此您可能需要根据您正在执行或分析的代码来决定在哪里引用它。
特别是,架构概述LLMEngine 清楚地描述了使用 vLLM 的入口点、核心类的行为以及其中的各种类层次结构。
再次,目的是为了了解以下三件事。 首先,我们通过代码了解一下架构,并确认线上和线下推理没有性能差异。
- 线上和线下推理没有性能差异

- 调度流程
- 批量推理和内存块管理的实际状态
vllm.LLM 请注意,在线推理是指向 OpenAI 兼容 API 发出请求并返回推理的格式,离线推理是指直接使用类或LLMEngine 类进行推理的格式。
在线推理:启动FastAPI服务器并生成EngineClient
首先,我将说明一下大致的结构。
当您使用 vLLM 启动服务器时,将使用下图所示的配置来处理默认设置。

vLLM 的 OpenAI 兼容服务器
在内部,引擎客户端 ( EngineClient )LLMEngine 配置为与推理引擎 ( ) 通信。 (图中引擎客户MQLLMEngineClient 端为下面提到的具体实例)
EngineClient 异步接受 API 请求并LLMEngine 通过相应地通信进行推断。
以下是从入口点开始的处理流程。
サーバの起動
vllm.entrypoints.launcher.serve_http()
FastAPIの状態の初期化
vllm.entrypoints.openai.api_server.init_app_state()
FastAPIアプリの構築
vllm.entrypoints.openai.api_server.build_app()
EngineClientの生成
vllm.entrypoints.openai.api_server.build_async_engine_client()
vllm.entrypoints.openai.api_server.build_async_engine_client_from_engine_args()
vllm.entrypoints.openai.api_server.run_server()
对于在线推理处理,vllm.entrypoints.openai.api_server.run_server() 入口点是启动兼容 API 的服务器。
我们先来看看这个。 此函数启动 OpenAI API 兼容服务器并使用 uvicorn 启动服务器。
其工艺流程如下。
EngineClient的一代- 构建 FastAPI 应用程序
- 初始化 FastAPI 状态
- 启动服务器
1.EngineClient 生成
vllm.entrypoints.openai.api_server.build_async_engine_client() 将EngineClient 被生成。 该客户端是与推理机通信的类,配置推理机的生成和通信。
AsyncLLMEngine 或者作为基于您的配置的具体实例MQLLMEngineClient 。 目前(截至 2024 年 11 月 25 日),默认设置MQLLMEngineClient 会生成尽可能多的.
两个引擎客户端都支持相同的 IF,因此以下MQLLMEngineClient 描述是假设的。 详细内容将在后面解释。
之后,在多个进程中启动推理引擎,并MQLLMEngineClient 生成并设置实例。
2. 构建 FastAPI 应用程序
vllm.entrypoints.openai.api_server.build_app() FastAPI 应用程序已构建。 该应用程序提供 OpenAI API 兼容端点。
FastAPIAPIRouter 是vllm/entrypoints/openai/api_server.py 全局定义的,以下三个端点定义为直接参与推理的部分。
@ router.post ( “/v1/chat/completions” ) async def create_chat_completion (请求: ChatCompletionRequest, raw_request:请求): … @ router.post ( “/v1/completions” ) async def create_completion (请求:CompletionRequest,raw_request:请求): … @ router.post ( “/v1/embeddings” ) async def create_embedding (请求: EmbeddingRequest, raw_request: 请求): …
目前最流行的可能是聊天完成 API,所以create_chat_completion() 我们从现在开始就看看它。
3.初始化FastAPI状态
vllm.entrypoints.openai.api_server.init_app_state() 使用 初始化 FastAPI 应用程序状态。 在这里,state 我们将链接FastAPI生成的推理引擎。
4. 启动服务器
vllm.entrypoints.launcher.serve_http() 您可以将 FastAPI 应用程序作为 HTTP 服务器启动,并使用 vLLM 开始在线推理。
在线推理:在 OpenAI 兼容服务器上接收请求
OpenAI 兼容服务器 vllm.entrypoints.openai.api_server.create_chat_completion() 接受请求。
其工艺流程如下。
- 请求预处理
- 向引擎发送请求
1. 请求预处理
self._preprocess_chat() 预处理请求。 尽管进行了各种详细处理,但处理的关键点是生成要输入到LLM的标记字符串。
在方法中conversation ,我们得到三个值:request_prompts , 。engine_prompts
conversation 是聊天完成 API 中常用的字典列表,格式如下:
对话=[ { “role” : “system” , “content” : "你是一个有用的助手。 " { “role” : “user” , “content” : “谁赢得了 2020 年世界大赛?” } ]
request_prompts 是所应用模型指定的格式chat_template 。 通常,它会被转换为以下格式:
request_prompts = '<|im_start|>system \n你是一个有用的助手。<|im_end|> \n <|im_start|>user \n谁赢得了 2020 年世界大赛?<|im_end|> \n <|im_start |>助理\n ’
最后,engine_prompts 是作为推理的直接输入的标记化字符串。 例如,如果将上述内容输入request_prompts 到 中Qwen/Qwen2.5-1.5B-Instruct ,则该值将如下所示。
引擎提示 = [ 151644 , 8948 , 198 , 2610 , 525 , 264 , 10950 , 17847 , 13 , 151645 , 198 , 151644 , 872 , 198 , 15191 , 2765 , 279 , 1879 , 4013 , 304 , 220 , 17 , 15 , 17 , 15 , 30 , 151645 , 198 , 151644 , 77091 , 198 ]
2. 向引擎发送请求
self.engine_client.generate() 通过引擎客户端向推理引擎发送推理请求。
在内部,首先asyncio 创建与请求对应的队列,并使用请求ID作为密钥向客户端注册请求队列。
接下来,向引擎发送生成指令。在本例中,假设为 ,因此将EngineClient 其包装并发送到处理进程。MQLLMEngineClient RPCProcessRequest
最后,提交的请求被推理引擎MQLLMEngine 接收run_engine_loop()
在线推理:生成 MQLLMEngine 并启动 LLMEngine
接下来,让我们按照生成包装器(通过调解与客户端的通信来控制推理引擎本身)MQLLMEngine 的流程,并启动推理引擎。
首先,我们看一下调用堆栈。
MQLLMEngineの起動
エンジンループ
リクエストの処理
self.handle_new_input()
self.handle_process_request()
self.engine.add_request()
推論の実行
self.engine_step()
self.engine.step()
engine.start()
self.run_startup_loop()
self.run_engine_loop()
LLMEngineの初期化
MQLLMEngine.init()
EngineClientの生成
vllm.engine.multiprocessing.engine.run_mp_engine()
vllm.engine.multiprocessing.engine.MQLLMEngine.from_engine_args()
处理概要如下。
MQLLMEngine初始化MQLLMEngine开始- 处理请求
1.MQLLMEngine 初始化
vllm.engine.multiprocessing.engine.run_mp_engine() 然后MQLLMEngine 运行发动机。
这很令人困惑,但这里创建的MQLLMEngine 并不是MQLLMEngineClient . MQLLMEngine 实际处理的是内部生成和维护的实例LLMEngine 。
vllm.engine.multiprocessing.engine.MQLLMEngine.from_engine_args() MQLLMEngine 在其中创建并LLMEngine 初始化。
这LLMEngine 是推理处理的主体,也是vLLM处理的关键。
2.MQLLMEngine 开始
engine.start() 将MQLLMEngine 开始。
具体来说,它在内部执行两个循环。
第一个self.run_startup_loop() 建立与Engine 和 的EngineClient IPC 通信。第二个self.run_engine_loop() 执行Engine 处理的主循环。
这是监控引擎状态并接受客户端请求的核心处理循环。
让我们更详细地self.run_engine_loop() 了解一下该过程。
首先,作为一个基本的循环过程,如果引擎没有正在处理的请求,它就会等待客户端的请求。
def run_engine_loop (self): “”“LLMEngine 的核心繁忙循环。”“” while True : if not self.engine.has_unfinished_requests(): # 轮询直到有工作要做 while self.input_socket.poll(timeout=POLLING_TIMEOUT_MS) == 0 : # 当没有工作时,检查引擎运行状况并发送 #健康状况返回给客户 self._health_check() self.engine.do_log_stats() logger.debug( “在引擎循环中等待新请求。” ) # 处理来自客户端的任何输入。 self.handle_new_input() # 引擎步骤。 request_outputs = self.engine_step() # 发送请求输出(如果是异步的,则在engine_step回调中完成) 如果 不是self.use_async_sockets: self._send_outputs(请求输出)
如果添加了新请求,则下一次调用会将新请求排队。
处理来自客户端的任何输入。 self.handle_new_input()
通过将内部LLMEngine 推理step() 推进一步,为排队的请求生成下一个令牌 。step() 内部engine_step() 称为 .
引擎步骤。 request_outputs = self.engine_step() # 发送请求输出(如果是异步的,则在engine_step回调中完成) 如果 不是self.use_async_sockets: self._send_outputs(请求输出)
3. 处理请求
self.handle_new_input() 处理来自客户的新请求。
在内部,self._handle_process_request() 我们进行错误处理并 self.engine.add_request() 调用将请求添加到引擎的请求队列中。
然后,self.engine_step() 调用将引擎的推理过程推进一步。
法学硕士发动机
LLMEngine 现在我们来看看vLLM处理的主体。
首先,作为概述,LLMEngine 内部加载模型并初始化内存,并 step() 使用方法进行推理处理。
另外,在上述在线推理处理中,最后一步是在 处添加请求,并在 处LLMEngine 执行 推理处理。handle_new_input() engine_step()
初始化LLM引擎
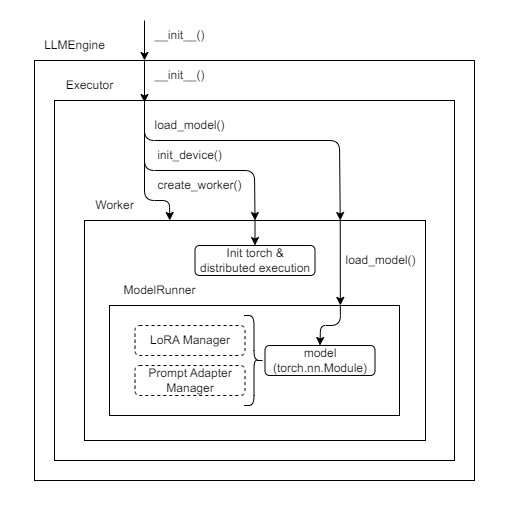
初始化LLM引擎
初始化过程如图所示,LLMEngine内部生成了几个类。 下面让我们展示一个粗略的调用堆栈。
スケジューラの初期化
vllm.core.scheduler.Scheduler.init()
self.scheduler.init_scheduler()
KVキャッシュの初期化
self.initialize_kv_caches()
利用可能メモリの決定
self.model_executor.determine_num_available_blocks()
self.driver_worker.determine_num_available_blocks()
VRAMの確保
self.model_executor.initialize_cache()
self.driver_worker.initialize_cache()
self.init_cache_engine()
CUDAGraphのキャプチャ
self.warm_up_model()
self.model_runner.capture_model()
Executorの初期化
executor_class.init()
self.model_executor.init_executor()
モデルロード
self.create_worker()
self.driver_worker.load_model()
self.model_runner.load_model()
LLMEngine.init()
其工艺流程如下。
- 初始化执行器
- 初始化KV缓存
- 调度程序初始化
1.执行器初始化
Executor 是管理执行状态的类,内部生成了其他类Worker ,ModelRunner 每个类根据自己的角色进行处理。
executor_class.__init__() Executor 执行初始化 。executor_class 如果 GPU 可用,则默认GPUExecutor 已解决。
Executor 初始化期间Worker 生成 。GPUExecutor 在这种情况下,Worker 该模型将管理每个单元一个 GPU。
调用层次很深,所以不再赘述,但最后一步是加载模型。 默认情况下,torch 加载过程由 执行。
2.初始化KV缓存
LLMEngine._initialize_kv_caches() 初始化KV缓存。 这里,为了利用 vLLM 的特征之一——分页注意力(Paged Attention),通过将内存划分为块来管理内存。
要计算具体的分配大小,determine_num_available_blocks() 请计算不会导致 OOM 的最大内存分配数量。 使用虚拟数据计算执行时的内存使用量和运行推理后的内存使用量,并通过将安装的 VRAM 乘以使用率获得的值减去峰值使用内存来计算可用内存。 默认利用率为0.9(90%的空闲空间用作KV缓存)。

GPU VRAM 上的模型和缓存
请注意,可以同时推断的请求数量取决于此处保护的 KV 缓存的大小。 然而,提示的大小根据LLM的要求而变化,并且生成的系列的长度也不是恒定的。 因此,vLLM 通过动态分配划分为块的内存区域,有效利用缓存,实现高速推理,同时最大化并发处理数量。
缓存大小CacheEngine.get_cache_block_size() 通过 获得。
key_cache_block = block_size * num_heads * head_size value_cache_block = key_cache_block 总计 = num_attention_layers * (key_cache_block + value_cache_block) 返回dtype_size * 总计
具体来说,它的值total 就是上面计算的结果乘以数据类型的大小。 默认情况下,block_size 指定 16, Size of a cache block in number of tokens. 因此默认情况下,每个块缓存 16 个令牌。
具体行为在文末确认。
最后vllm.worker.model_runner.ModelRunner._warm_up_model() ,预热模型。 预热是指启用称为 CUDA Graphs 的功能。 CUDA Graphs 似乎是一个允许您执行优化处理的功能,可以通过提前执行和捕获 CUDA 计算来再次调用该处理。
参见PyTorch 1.10の新機能「CUDA Graphs」のパフォーマンスを測定してみる - まったり勉強ノート
3.调度器初始化
vllm.core.scheduler.Scheduler.__init__() 初始化调度程序。
调度器是调度推理处理并管理模型推理处理的类。
在执行分布式推理时,有多少个并行调度器就会生成多少个调度器,但在这种情况下,为了简单起见,只会生成一个。
当在线接受推理请求时,所执行的处理量直到运行时才知道。 调度程序通过决定哪些请求正在进行中来解决这个问题。
请求可以处于运行、等待或交换状态,并在自己的队列中进行管理。
运行表示将执行下一次推理,等待表示尚未执行推理。
交换过程中,数据暂时保存在内存中主要是因为VRAM大小不足。 我们将尝试尽可能并行化推理,但如果生成序列很长,您可能会像最初预期的那样耗尽 VRAM。 在这种情况下,您可以暂时将内存保存到 DRAM 端,以释放 VRAM 并处理其他请求。

交换请求
详细内容将在后面解释。
LLMEngine 添加请求到

添加推理请求
LLMEngine.add_request() 将请求添加到引擎的请求队列中。 此时,它只是添加到待处理的请求中,尚未处理。
接受各种格式的请求,但此时执行预处理,并且由标记器标记的数字列表被格式化为对引擎的请求。
LLMEngine 推理处理
LLMEngine.step() 我们终于到达了推理过程的主体部分。
通过执行此操作,引擎的推理过程前进了一步,即生成下一个令牌。 即使只得到一个代币,从一开始就遵循这个过程也是一个漫长的过程。
调用堆栈大致如下所示:
モデルの実行
self.model_executor.execute_model()
self.driver_worker.execute_model(execute_model_req)
self.model_runner.execute_model()
model_executable()
スケジューリング
self.scheduler[virtual_engine].schedule()
self.schedule()
LLMEngine.step()
其工艺流程如下。
- 调度
- 运行模型
1. 日程安排

使用 LLMEngine.step() 执行推理
LLMEngine.step() schedule() 在内部,首先调用调度程序的方法。
稍后会单独讨论调度处理和时间线的具体示例,但作为一般经验,如果有新请求,则会优先处理,一旦没有新请求,就会调度处理同时尽可能多的请求。
基本上,等待的请求会按顺序移入执行,只要内存允许,所有请求都会同时处理,但如果内存紧张,它们会暂时交换。
2. 运行模型

运行模型
模型的执行LLMEngine.model_executor.execute_model() 是在 中完成的。 如上图所示,最终结果torch 就是模块的执行。
然而,CUDA Graphs 用于内部处理以加快处理速度。
离线推理:LLMEngine 直接执行
我们确认,在在线推理处理中,LLMEngine 生成了 的实例,并通过它添加请求并进行推理处理。
离线推理处理怎么样?
首先我们看一下官方LLM Engine示例的处理。
综上所述,官方LLM Engine示例的基本处理 与MQLLMEngine .run_engine_loop()
下面的process_request() 和前面的一run_engine_loop() 对比,几乎是一样的。 这个例子LLMEngine 就是一个如何操作的例子,自然会这么说。
def process_requests(引擎:LLMEngine, test_prompts: List[Tuple[ str , SamplingParams]]): “”“持续处理提示列表并处理输出。”“” request_id = 0 while test_prompts或engine.has_unfinished_requests(): if test_prompts: 提示,sampling_params = test_prompts.pop( 0 ) engine.add_request( str (request_id), 提示, 采样参数) 请求 ID += 1 request_outputs: List[RequestOutput] = engine.step() 对于request_outputs中的request_output : if request_output.finished: print (request_output)
离线推理:vllm.LLM 使用类
主要问题是离线推理vllm.LLM 在使用类时是否可以获得与在线推理相同的结果。在实现vLLM离线推理处理时,经常会引入以下示例代码。
如果这段代码的处理结果与在线推理时的处理相同,那么可以说差异主要在于提供方法。
从vllm导入LLM,SamplingParams # 提示示例。 提示=[ “你好,我的名字是”, “美国总统是”, “法国首都是”, “人工智能的未来是”, ] # 创建采样参数对象 Sample_params = SamplingParams(温度= 0.8 , top_p= 0.95 ) # 创建一个 LLM.llm = LLM(model= “facebook/opt-125m” ) # 根据提示生成文本。 # 输出是包含提示、生成的文本和其他信息的 RequestOutput 对象列表。 输出= llm.generate(提示,sampling_params) # 打印 输出的输出: 提示=输出.提示 generated_text = output.outputs[ 0 ].text print (f “提示: {prompt!r}, 生成文本: { generated_text!r}” )
此代码LLM 通过类使用 vLLM 的推理功能,但内部LLMEngine 推理过程是使用 .
此外,每个提示,无论是作为单个提示还是作为列表给出,LLMEngine.add_request() 都通过 向引擎请求。
法学硕士课程: … def _add_request ( 自己, 提示:提示类型, 参数:联合[SamplingParams,PoolingParams], lora_request:可选[LoRARequest] = None, Prompt_adapter_request:可选[PromptAdapterRequest] = None, 优先级:int = 0, ) ->无: request_id = str (下一个(self.request_counter)) self.llm_engine.add_request( 请求ID, 迅速的, 参数, 劳拉_请求=劳拉_请求, 提示_适配器_请求=提示_适配器_请求, 优先级=优先级, )
因此,无论是线下还是线上的推论,最终LLMEngine.add_request() 都是被调用的。
LLM 无论您使用类还是通过 API 发送请求, LLMEngine 只是发送请求的方式不同,核心引擎本身的行为保持不变。
时间很长,不是吗?我们终于达到了最初的目标。我们发现 vLLM 中在线和离线推理的性能没有差异。 但它会持续更长的时间。
vLLM 批量请求处理
vLLM 具有接收文件并进行推理的功能,相当于OpenAI的 Batch API 。 (严格来说)这也用于执行推理处理。jsonl run_batch.py LLMEngine AsyncLLMEngine
最后vllm.entrypoints.openai.serving_chat.OpenAIServingChat ,create_chat_completion() 您 jsonl 只需调用尽可能多的有效请求。
稍微令人困惑的部分是,AsyncLLMEngine 引擎本身EngineClient 是 的一种类型,并且引擎本身LLMEngine 继承自_AsyncLLMEngine 。
class AsyncLLMEngine (EngineClient): “”“LLMEngine` 的异步包装器。”“” … _engine_class:类型[_AsyncLLMEngine] = _AsyncLLMEngine
class _AsyncLLMEngine (LLMEngine): “”“LLMEngine 的扩展以添加异步方法。”“” …
AsyncLLMEngine _AsyncLLMEngine 持有 inside的一个实例。处理通过MQLLMEngineClient 调用排队,与调用LLMEngine.add_request() 类似 。_AsyncLLMEngine.add_request_async() AsyncLLMEngine
create_chat_completion() 核心引擎的行为在这里保持不变,EngineClient.generate() 只调用抽象。run_batch
 请求调度
请求调度
现在,第一部分太长太沉重,无法继续,但我终于可以继续我的第二个目标了。
- 在线和离线推理之间没有性能差异。
- 调度 流程
- 批量推理和内存块管理的实际状态
这就是vLLM的调度处理 。
为了实现高效的批量推理,vLLM 会安排在每个推理步骤应处理哪些请求。
首先,vLLM 处理阶段以两种状态进行管理:
类 SequenceStage (enum.Enum): 预填充 = enum.auto() 解码 = enum.auto()
PREFILL 是对输入提示的评估,这对 GPU 的处理负载要求很高。 DECODE 是对下一个生成的令牌的评估,这是一个需要 GPU 上高内存负载的过程。
默认情况下, PREFILL 它会优先安排目标请求以同时处理尽可能多的请求。
下面概述了具体的默认调度逻辑,但下图显示了每个请求每次添加到 LLMEngine 时是如何处理的。

推理处理时间线
可以同时处理的请求数量是max_num_seqs 有限的,这也与接下来解释的批量推理的实际状态有关。
具体调度逻辑
首先,如果没有序列组(≒request)被交换, PREFILL 则考虑将目标进程从等待队列调度到下一个执行目标。
不是无条件添加的,但只要自上次接收时间起经过一定时间(≒不低于延迟上限*)并且有一个序列组正在等待(SequenceStatus = WAITING ),就可以我们将在此步骤中选择合适的目标作为候选。
*如果满足以下条件。
通过延迟 = ( (现在 - 最早到达时间)> (self.scheduler_config.delay_factor * self.last_prompt_latency) 或 不自运行)
添加时也会考虑提示长度。
如果提示长度不超过模型输入大小并且可以分配到VRAM,则最终添加到运行队列中(改为SequenceStatus = )。RUNNING
超过提示长度或由于内存大小而被确定为无法推断的目标序列,即使它们没有超过提示长度,FINISHED_IGNORED 也会被标记并排除在推断目标之外。
应用LoRA时,即使同时可以读取的LoRA数量超过上限,也会被返回到等待队列中,等待下一步。
PREFILL 如果到目前为止已经调度了目标处理,则本步骤不会调度解码目标。 如果不是,则安排解码处理。 因此,使用默认的调度逻辑,运行队列将仅PREFILL 包含DECODE
另外,在调度解码目标时,如果有空闲空间,则交换过程将重新启动。
执行状态定义为一个Enum,如下,当状态达到大于2的值时,就认为已经完成。
class SequenceStatus (enum.IntEnum): “”“序列的状态。”“” WAITING = 0 RUNNING = 1 SWAPPED = 2 # 注意:SWAPPED ( 2) 之后 的任何内容都将被视为 完成状态。 = 4 已完成_中止 = 5 已完成_忽略 = 6 @ staticmethod def is_finished (status: “SequenceStatus” ) → bool : 返回状态 > SequenceStatus.SWAPPED
块状预填充
如果设置了Chunked Prefill (*),则调度策略会略有不同。 这次,我将省略此操作的详细内容,仅提供概述。
分块预填充是一种大致优先PREFILL 于的设置。DECODE 如一开始的图所示,默认调度处理PREFILL 只要有目标进程就优先处理, 直到DECODE 目标进程用完PREFILL 才生成下一个令牌。 这是一种最小化请求 TTFT(首次令牌时间)的策略。
但是,DECODE 等待目标进程意味着该请求的 ITL(令牌间延迟)将会增加。
顾名思义,Chunked Prefill是PREFILL 通过将进程划分为 chunk,将DECODE 进程与目标进程一起进行批量处理的功能。
虽然这取决于具体情况,但官方声明指出“吞吐量可能会根据设置而降低。” 您需要实际尝试一下才能知道效果如何,但这在某种程度上似乎是 TTFT 和 ITL 之间的权衡。
 批量推理和内存块管理的实际状态
批量推理和内存块管理的实际状态
第二个长度不错。 现在,让我们继续讨论批量推理和内存块管理的第三个也是最后一个方面 。
- 在线和离线推理之间没有性能差异。
- 调度流程
- 批量推理和内存块 管理的实际状况
虽然叫batch inference,但是这个流程到底是如何启动的,而被引为改进的Paged Attention在实际执行的时候又如何看呢?
首先,批处理的主体对应于vLLM当前实现中的CUDA Graphs重放。
目前cuda graph仅受解码阶段支持。
如代码中所述,此时model_executable中检索到的是CUDA Graph。
#目前 cuda graph仅受解码阶段支持。 prefill_meta = model_input.attn_metadata.prefill_metadata 解码元 = model_input.attn_metadata.decode_metadata # TODO : 一旦所有 虚拟引擎共享相同的 kv 缓存,我们就可以删除它。 虚拟引擎=模型输入.虚拟引擎 如果prefill_meta为 None 且decode_meta.use_cuda_graph: 断言model_input.input_tokens不是 None graph_batch_size = model_input.input_tokens.shape[ 0 ] model_executable = self.graph_runners[虚拟引擎][ 图批量大小] 别的: model_executable = self.model
在此代码中,我graph_batch_size 获取批量大小并 获取graph_runners 注册的.model_executable
捕获 CUDA 图形
预捕获的runner如下,最多注册256批次的CUDA Graph。

捕获的 CUDA 图
计算运行时捕获 CUDA 图形时假设的批量大小 batch_size_capture_list ,上限self.max_batchsize_to_capture 为 。
graph_batch_size = self.max_batchsize_to_capture 批量大小捕获列表 = [如果bs <= graph_batch_size,则bs为_BATCH_SIZES_TO_CAPTURE中的 bs ]
_BATCH_SIZES_TO_CAPTURE 定义在下面的代码中:
_BATCH_SIZE_ALIGNMENT = 8 # cudagraph 可以捕获的所有令牌大小。 # 它们可以是任意大。 # 目前包括:1, 2, 4, 8, 16, 24, 32, 40, … , 8192. # 捕获的实际大小将由模型决定, # 取决于模型的 max_num_seqs。 #注意:如果此列表更改,则需要更新 _get_graph_batch_size _BATCH_SIZES_TO_CAPTURE = [ 1 , 2 , 4 ] + [ 。 _BATCH_SIZE_ALIGNMENT * i表示i在 范围( 1 , 1025 )内 ]
如果继续这样下去,看起来最多会注册 8192 个,但实际上,如注释中所述, 最大值self.max_batchsize_to_capture 由_get_graph_batch_size()
self.max_batchsize_to_capture = _get_max_graph_batch_size( self.scheduler_config.max_num_seqs)
这里,_get_max_graph_batch_size() 实现如下,源自self.scheduler_config.max_num_seqs 给定的 LLMEngine 配置。max_num_seqs 默认值为 256,因此最多将注册 256 个 CUDA 图(如图所示)。
参见https://docs.vllm.ai/en/stable/models/engine_args.html
def _get_max_graph_batch_size (max_num_seqs: int ) → int : “”" max_num_seqs:批次中的最大序列数。 _BATCH_SIZES_TO_CAPTURE:我们要捕获的所有大小。 如有必要,可以通过调用 _get_graph_batch_size 来填充 max_num_seqs, 这将处理一些边缘情况,例如 1、2、4。 如果填充的大小在_BATCH_SIZES_TO_CAPTURE中,则返回填充的大小, 如果不在,则表示填充的大小大于 _BATCH_SIZES_TO_CAPTURE中的最大大小,则返回_BATCH_SIZES_TO_CAPTURE中的最大大小 “”" 。 padded_size = _get_graph_batch_size(max_num_seqs) 如果_BATCH_SIZES_TO_CAPTURE中有pagged_size : 返回pagged_size 断言ppped_size > _BATCH_SIZES_TO_CAPTURE[- 1 ] 返回_BATCH_SIZES_TO_CAPTURE[- 1 ]
如果实际批次数不完全匹配
如果批次号不完全匹配,请获取最接近的可能批次大小。 例如,当有 5 个正在运行的请求时,我们在推理之前查看批量大小,如下所示。

在执行前检查批量大小
graph_batch_size 是 8,因此看来将启动可以执行该批处理的最小 CUDA Graph。 在实际处理中,小于默认批量大小的量被计算为填充量,并且对于该大小,填充量用零填充。
这允许您通过填充 CUDA 图来利用它们,即使它们不一定与捕获的 CUDA 图的批量大小匹配。
cuda_graph_pad_size = self._get_cuda_graph_pad_size( num_seqs = len(seq_lens), max_decode_seq_len = max_decode_seq_len, max_encoder_seq_len = max_encoder_seq_len) batch_size = len (input_tokens) if cuda_graph_pad_size != - 1 : # 如果可以使用 cuda graph,则相应地填充张量 # 有关更多详细信息,请参阅 capture_model API。 # vLLM 仅将 cuda graph 用于解码请求。 批量大小 += cuda_graph_pad_size #令牌和位置。 input_tokens.extend(itertools.repeat( 0 , cuda_graph_pad_size) )断言self.runner.device不是 None input_tokens_tensor = async_tensor_h2d(input_tokens, torch.long, 自跑步设备, self.runner.pin_memory) token_types_tensor = async_tensor_h2d(token_types, torch.long, 自跑步设备, self.runner.pin_memory) \ if token_types else None
分页注意力(非连续 VRAM 使用)
如上所述,实现 vLLM 的一个主要巧妙之处在于它使用类似于操作系统内存管理的分页式 VRAM 管理。 这使得操作可以按需分配尽可能多的内存到预先确保的KV缓存区域。
默认情况下,内存将 16 个令牌视为一个块。 如果包含输入提示的序列的长度超过此块大小,则该序列将被拆分为多个块。
详细看一下操作,比如输入提示长度为9,生成token个数为12,则总共会缓存21个token,会被分成两个块。

block_tables 有两个块

有16个或更多提示+输出标记
另一方面,如果输入提示长度为9,生成的代币数量为1,则区块数量为1。

block_tables 有一个块

少于16个提示+打印标记
从Python代码方面来看,令牌可以看作是一系列的,但在GPU上实际执行处理时,会引用该块对应的内存区域。
如果您在模型执行之前查看似乎是块表的数据,您将看到与上图所示的块编号和预期值类似的值。现在可以将其引用为火炬张量。
解码元.块表 张量([[13058, 13056, 0, …, 0, 0, 0], [13057, 13055, 0, …, 0, 0, 0], [13054, 0, 0, …, 0, 0, 0], …, [ 0, 0, 0, …, 0, 0, 0], [ 0, 0, 0, …, 0, 0, 0], [ 0, 0, 0, …, 0, 0, 0]], 设备=‘cuda:0’, dtype=火炬.int32)
这种分析是使用调试器的优点之一。
结论
以上是阅读vLLM代码的日志。 我很好奇有多少人读了这篇文章而没有一开始就放弃…
虽然vLLM是一个很大的项目,但是在OSS中显得比较小。 尝试后我的印象是它非常容易阅读。 然而,这并不是说这很容易,我认为跟上代码的困难是由于活动导致的快速变化,而不是由于项目规模而导致的复杂性。
即使使用众所周知的软件和库,大多数人也会习惯它们,并且可能不会跟进它们的实施。 从实现中了解什么样的逻辑在起作用将有助于您理解如何使用软件或库。
此外,阅读代码应该可以帮助您理解软件或库的原理。 我确信它对于产品开发也很有用。
那么,谢谢你的辛勤工作。