FSDP(Fully Sharded Data Parallel) 是 PyTorch 中的一种分布式训练技术,用于高效地训练大规模模型。它的核心思想是通过对模型权重和梯度的切片和分片(sharding),减少显存使用和通信开销。FSDP 的主要应用场景是大模型训练,尤其是在显存有限的 GPU 集群上。
Pytorch中关于FSDP的博文:
- Getting Started with Fully Sharded Data Parallel (FSDP2) — PyTorch Tutorials 2.10.0+cu130 documentation
- https://pytorch.org/blog/training-using-float8-fsdp2/
- https://pytorch.org/blog/maximizing-training-throughput/
FSDP2 的出现为训练超大规模模型提供了高效、低成本的解决方案,是当前 PyTorch 分布式训练的核心技术之一。
本文展示了如何通过 FSDP2、DTensor 和 torch.compile,结合 torchao 的 float8 优化,实现相较于 FSDP1 bf16 training 速度高达 50% 的提升,同时保持损失函数和评估基准的相等性。这些改进适用于多种 Meta LLaMa 模型架构,涵盖从 1.8B 参数的小模型到 405B 参数的大模型,使得训练效率显著提高。
我们利用 Meta Llama3 架构进行了实验,并在两个规模下(8B 模型在 100B tokens 数据集,70B 模型在 50B tokens 数据集)进行了模型质量研究,验证 float8 和 bf16 训练损失曲线的完全一致性。
此外,我们用 FineWeb-edu 数据集训练了一个 3B 模型到 1T tokens,并运行标准评估基准,确保模型质量与 bf16 保持一致。
什么是 Float8?
float8 训练格式由 NVIDIA、ARM 和 Intel 在 2022 paper 首次提出,表明可以在保持模型质量的前提下使用低精度的 float8 进行训练。NVIDIA Hopper 系列 GPU 的出现使得 FP8 训练成为可能,通过支持原生 float8 tensor core,训练吞吐量可提高超过 2 倍。
实现 float8 训练的难点主要有三点:
- 支持核心模型操作(如 matmul 和注意力机制)的 float8 实现;
- 支持分布式框架中的 float8 训练;
- 支持 GPU 之间的 float8 权重通信。
其中,NVIDIA 库已支持 float8 matmul 操作,FSDP2 和 torchao 提供了后两者的支持。
In this blog, we are using torchtitan as the entry point for training, IBM’s deterministic data loader, the
float8linear layer implementation from torchao, and thefloat8 all gatherfrom the latest PyTorch nightlies in conjunction with FSDP2. For this training, we are using the float8 per tensor (tensorwise) scaling granularity rather than rowwise. We leveragetorch.compileto ensure that we get maximum performance gains. We are computingattentioninbf16using SDPA and are currently working on moving this to float8 as well.
实验结果
我们进行了多项实验以展示使用 float8 进行训练的优势,**首先确保模型质量不会因低精度训练而受损。**为验证这一点,我们分别训练了一个 8B 模型和一个 70B 模型,并进行了几千步的训练,比较了 float8 和 bf16 训练的损失曲线。
实验在三种不同的 H100 GPU 集群环境下进行,以证明结果的可复现性,这些集群配置如下:
-
Meta 的 Grand Teton,配备 400Gbps 的自定义互连;
-
IBM 研究集群,支持 3.2Tbps 的 Infiniband 互连;
-
IBM Cloud 集群,支持 3.2Tbps 的 RoCE 互连,用于 GPU 间通信。
随后,我们绘制了这两个模型的损失曲线比较(如下图所示),以展示在训练几千步后,float8 和 bf16 的损失收敛性保持一致。
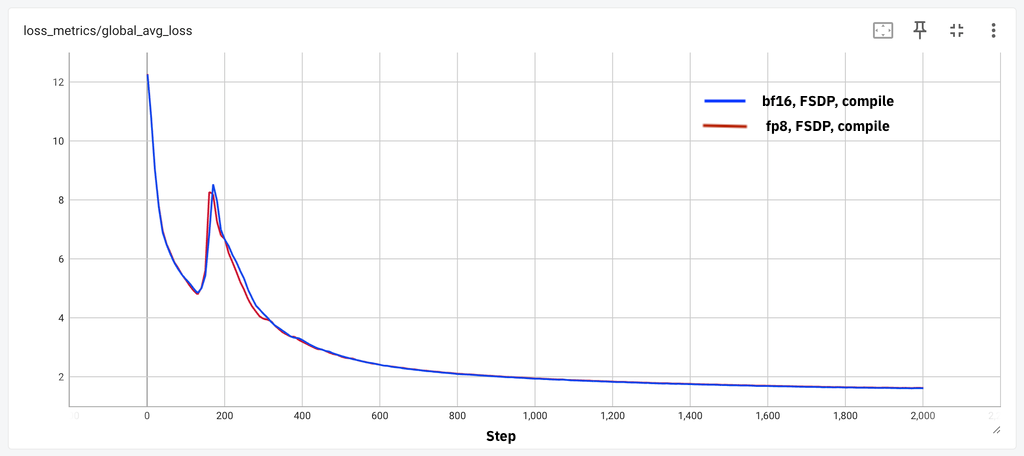
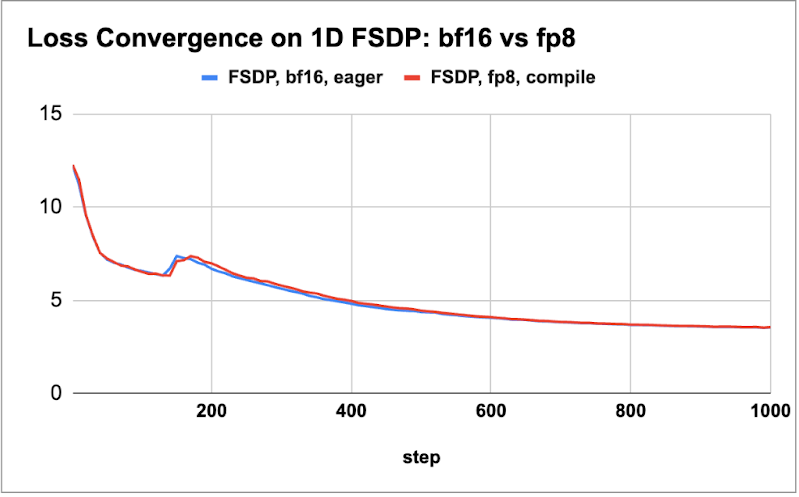
Figure 1: (a) 8B model loss parity for 2k steps, (b) 70B loss parity for 1k steps
我们观察到,在不同的模型和实验环境下,float8 和 bf16 在小规模 token 训练中均能实现损失一致性(loss parity)。接下来,我们对四种不同规模模型(从 1.8B 到 405B)的吞吐量提升进行了评估。
我们针对 float8 和 bf16 训练分别探索了最佳的批量大小和激活检查点方案,以计算每 GPU 的 token 处理速率(tokens/sec/GPU, wps),并报告性能增益。对于 405B 模型,我们利用了 FSDP2 中的 DTensor 进行张量并行训练。所有测量均使用了 8K 的序列长度。
| Model size | wps (bf16) | wps (float8) | Percent gain |
|---|---|---|---|
| 1.8B | 29K | 35K | 18% |
| 8B | 8K | 10K | 28% |
| 70B | 956 | 1430 | 50% |
| 405B (TP4) | 149 | 227 | 52% |
Table 1: Performance gains over bf16 (both bf16 and float8 use torch.compile)
我们从表 1 中观察到,对于更大的模型(70B 和 405B),性能提升可达到 50%,而较小的模型性能增幅在 20% 到 30% 之间。在进一步的实验中,我们发现引入 float8 的 all_gather 操作,可以在仅使用 float8 计算的基础上再额外提升约 5% 的性能,这与 AWS 博客 中的观察结果一致。
其次,为了展示 FP8 模型的有效性,我们按照 Llama3 的架构训练了一个 3B 参数规模的模型,对 1T tokens 进行了训练,所使用的数据集为 Hugging Face 提供的 FineWeb-edu 数据集。我们使用 lm-eval-harness 框架进行了评估,并在下表中展示了一部分结果。我们观察到,bf16 模型的性能略优于 float8 模型(大约高出 1%)。
尽管某些评估指标在 bf16 模式下表现显著更好(例如,MMLU 高出 3 分),我们预计随着超参数的进一步优化以及更大规模的训练(例如,bf16 的实验使用了只有一半大小的批量,而众所周知,较小批量训练可以改善评估得分),这些差距会逐渐消失。
| Benchmark | Score (float8) | Score (bf16) |
|---|---|---|
| MMLU (5-shot) | 0.26 | 0.29 |
| ARC-e | 0.73 | 0.73 |
| ARC-c | 0.43 | 0.46 |
| Hellaswag | 0.65 | 0.67 |
| sciq | 0.89 | 0.88 |
| OpenBook QA | 0.43 | 0.43 |
| PIQA | 0.76 | 0.76 |
| Winogrande | 0.60 | 0.65 |
| Average | 0.59 | 0.60 |
Table 2: Benchmark scores for float8 trained model running in FP16 for eval (at 1T tokens of FineWeb pre-training).
最后,我们将实验扩展到 IBM Cloud 集群中的 512 个 H100 GPU。在这种规模下,我们成功地复现了先前观察到的结果和加速效果,即使在 512 GPU 的规模上依然有效。以下表格总结了这些结果,仅针对大模型(70B 和 405B)。
| Model size | wps (bf16) | wps (float8) | Percent gain |
|---|---|---|---|
| 70B | 960 | 1448 | 51% |
| 405B (TP4) | 152 | 217 | 43% |
Table 3: Performance gains over bf16 (both bf16 and float8 use torch.compile) for 512 GPU scale
未来工作
我们将探索其他形式的并行训练(如上下文并行)以及这些特性在大规模模型训练中的可组合性。