翻译自:https://medium.com/squeezebits-team-blog/vllm-vs-tensorrt-llm-1-an-overall-evaluation-88f281bf01c7
该文章测试了最新版(9.15)trt-llm和vllm的性能,不过文中没有提到是否使用vllm在0.6.0版本更新的Multi-step Scheduling。
vLLM 和 TensorRT-LLM 是我们熟知的大型语言模型(LLM)推理框架。 vLLM 是一个快速且易于使用的库,支持在多种设备上进行 LLM 推理和服务,包括 NVIDIA、AMD 和 Intel 的 GPU。相对地,TensorRT-LLM 是一个高度优化的工具箱,专门为加速 NVIDIA GPU 上的推理性能而设计。两者都旨在最大限度地提高推理速度和资源利用率,同时尽量减少延迟。
本文直观比较了 vLLM 和 TensorRT-LLM。为了保证公平的评估,我们选择了一个常用的 LLM 模型和行业标准的 NVIDIA GPU:Llama-3-8B 和 A100-SXM 80G GPU。我们使用了两者的默认设置进行评估,并探索了在特定实际场景下更优的配置。我们的目标是为实践者提供有价值的见解,以帮助他们为 LLM 部署策略选择最合适的解决方案。
前期准备
了解 LLM 服务中的关键指标
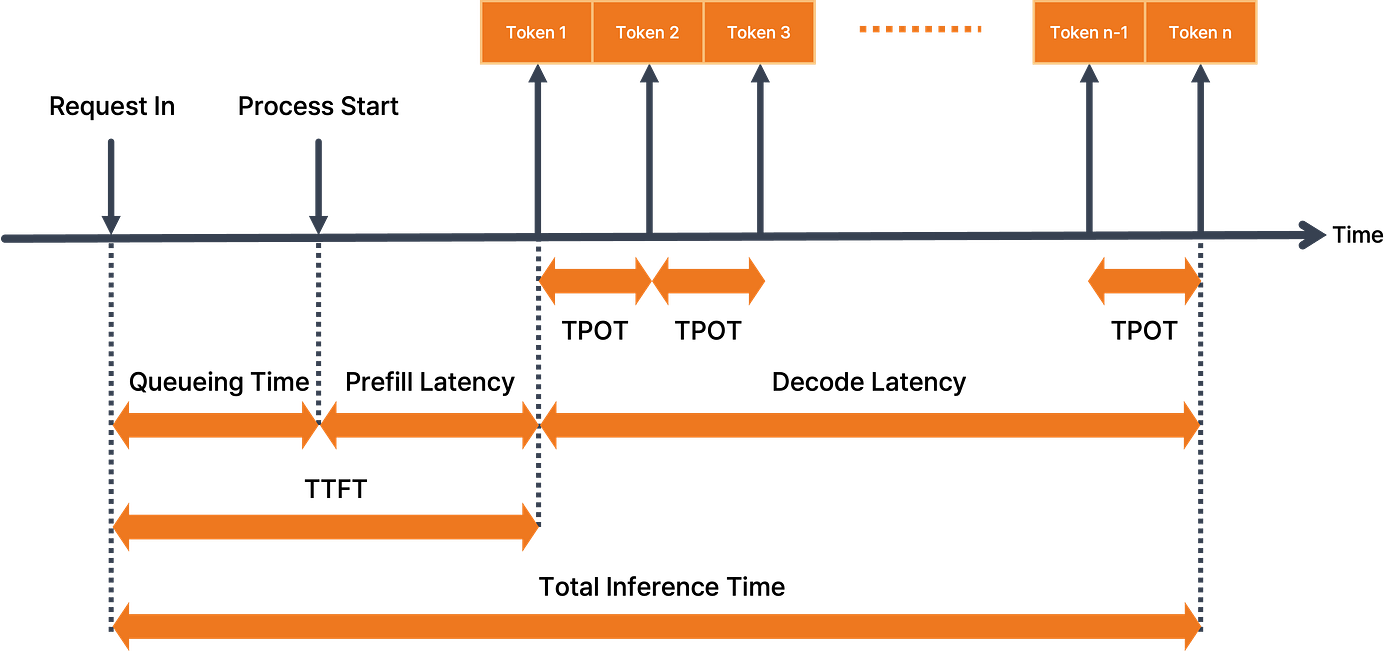
评估 LLM 性能需要理解三个关键指标:吞吐量、首token响应时间(TTFT)和单token生成时间(TPOT)。各指标和相关参数如 图 1 所示。
吞吐量(Tokens/s)
• 吞吐量指系统在单位时间内生成的令牌数量。它通过生成的令牌总数除以总推理时间来计算。较高的吞吐量意味着系统可以高效处理大量请求,这对于实时应用和同时服务大量用户至关重要。
首token响应时间(TTFT,秒)
• TTFT 衡量从接收到请求到生成第一个令牌的延迟。该指标对用户体验至关重要,尤其是在需要即时反馈的交互式应用中。较低的 TTFT 表示初始响应更快,应用更具响应性。
单token生成时间(TPOT,毫秒)
• TPOT,也称为token间延迟(ITL),是生成每个后续token的平均时间。该指标反映了推理期间模型的token生成速度。较低的 TPOT 结果意味着更快且更流畅的token生成过程。
通过监控和优化吞吐量、TTFT 和 TPOT,实践者可以在模型部署、资源分配和系统配置方面做出更明智的决策。因此,我们在比较 vLLM 和 TensorRT-LLM 时重点关注这些性能指标。
实验设置
基准数据集
在所有实验中,我们使用了具有固定输入和输出长度的数据集,以确保两种框架处理的token数量一致。vLLM 和 TensorRT-LLM 都支持创建由随机token组成的固定长度数据集。在 vLLM 中,输入和输出长度直接提供给 benchmark_serving.py 脚本,而在 TensorRT-LLM 中,数据集通过 prepare_dataset.py 脚本生成。
框架版本
我们选择了能够成功完成基准测试的两个框架的最新版本。对于 vLLM,我们使用了 v0.6.1(commit 530821d0),对于 TensorRT-LLM,我们使用了 0.14.0dev2024091000,并使用了 C++ API。
模型和硬件
• 模型:Llama-3-8B(BF16)
• 硬件:NVIDIA A100-SXM 80G GPU
默认配置下的性能表现
• 工作负载:四个随机数据集,每个包含 4096 个样本,固定的输入和输出长度为:(128, 128)、(2048, 128)、(128, 2048)、(2048, 2048)
我们使用具有不同输入和输出长度组合的数据集对 vLLM 和 TensorRT-LLM 的默认设置进行了评估。为了防止内存相关的错误,最大序列长度设置为每个数据集的输入和输出长度之和,其他设置保持默认。
结果
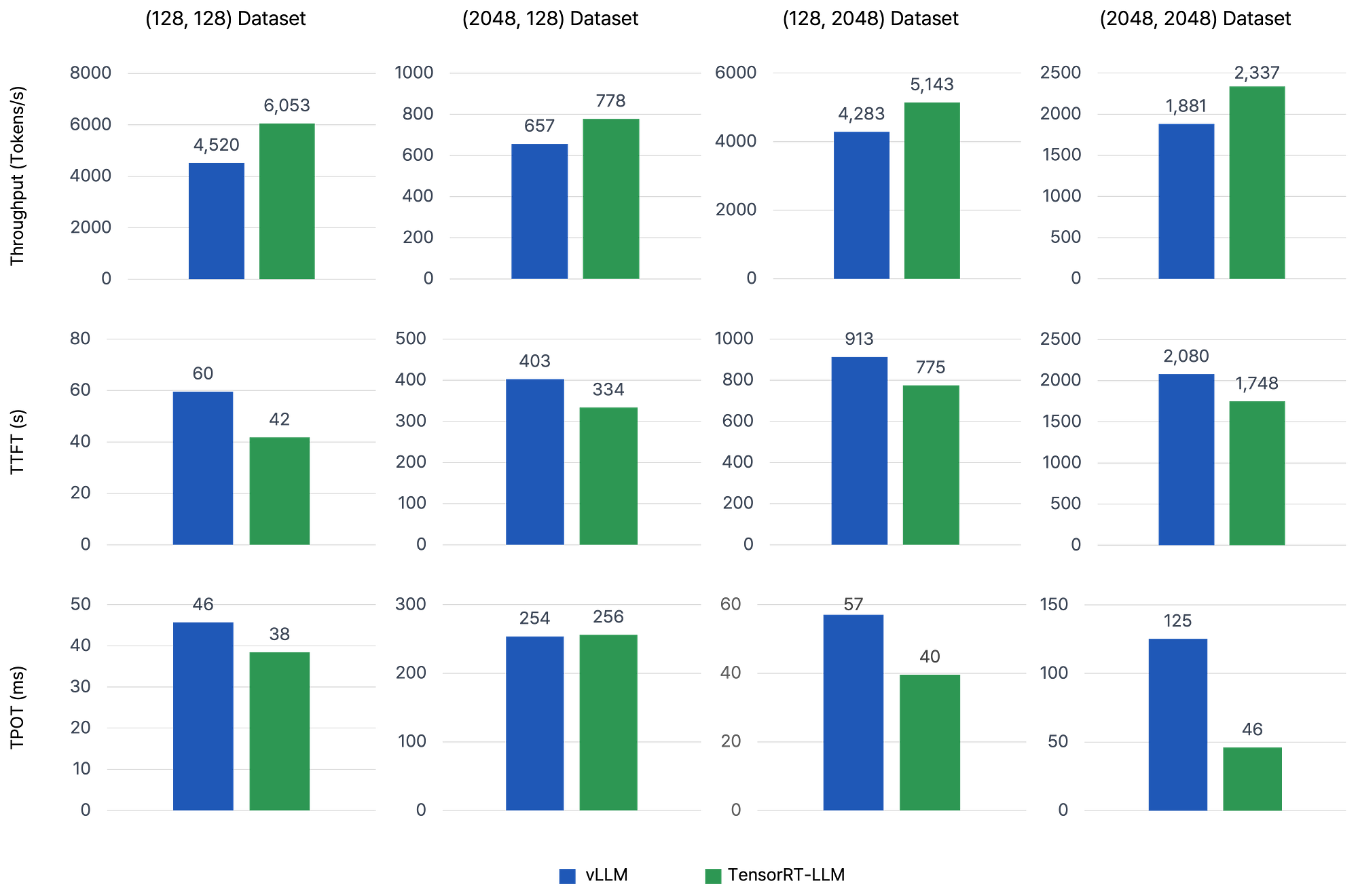
如 上图 图 2 所示,TensorRT-LLM 在所有指标上均表现优于 vLLM,特别是在输入和输出长度较短的数据集中,TensorRT-LLM 的 吞吐量 比 vLLM 高 1.34 倍。而在输入和输出长度较长的数据集中,TensorRT-LLM 在 TPOT 上表现出 2.72 倍 的提升。
不过,两种框架在 (2048, 128) 数据集 上的整体指标差异不大。因此,在接下来的部分中,我们重点关注这个数据集,详细探讨不同配置在实际场景中的性能表现。
最后,由于默认请求速率设置为无限,两种框架在 TTFT 方面表现出极高的数值。关于请求速率与 TTFT 的关系将在后续部分中详细讨论(见 图 5)。
场景1:TPOT 受限场景
在上一节中,我们比较了 vLLM 和 TensorRT-LLM 在默认配置下的性能表现。然而,在许多实际应用中,通常存在特定的服务要求。在这种情况下,默认配置可能不适用,需要进行额外的优化以满足要求。
在这个场景中,TPOT 是关键约束。TPOT 是与用户体验密切相关的指标,优化 TPOT 以加快令牌生成速度通常是 LLM 服务的优先事项(参见 Groq 的 800 token-per-second 演示)。场景1 的设置如下:
• 工作负载:随机数据集包含 4096 个样本,固定输入和输出长度为 (2048, 128)
• 要求:TPOT 必须小于 20ms
• 目标:最大化吞吐量
在场景#1 中,两种框架的默认配置都无法满足严格的 TPOT 约束,因此需要对默认设置进行调整。
TPOT 与批次大小
对于 vLLM 和 TensorRT-LLM,我们可以通过控制多种选项来最小化 TPOT。在所有选项中,我们选择控制 批次大小。
批次大小 在平衡 TPOT 和 吞吐量 中起着关键作用。较大的批次大小意味着推理负载更重,从而提高吞吐量,而较小的批次大小则会加快推理迭代(降低 TPOT)。
我们通过改变 vLLM 和 TensorRT-LLM 的最大批次大小进行了实验,其他框架设置与默认配置保持一致。该实验的目标是找到在满足 TPOT 约束的同时最大化吞吐量的最佳批次大小。
结果
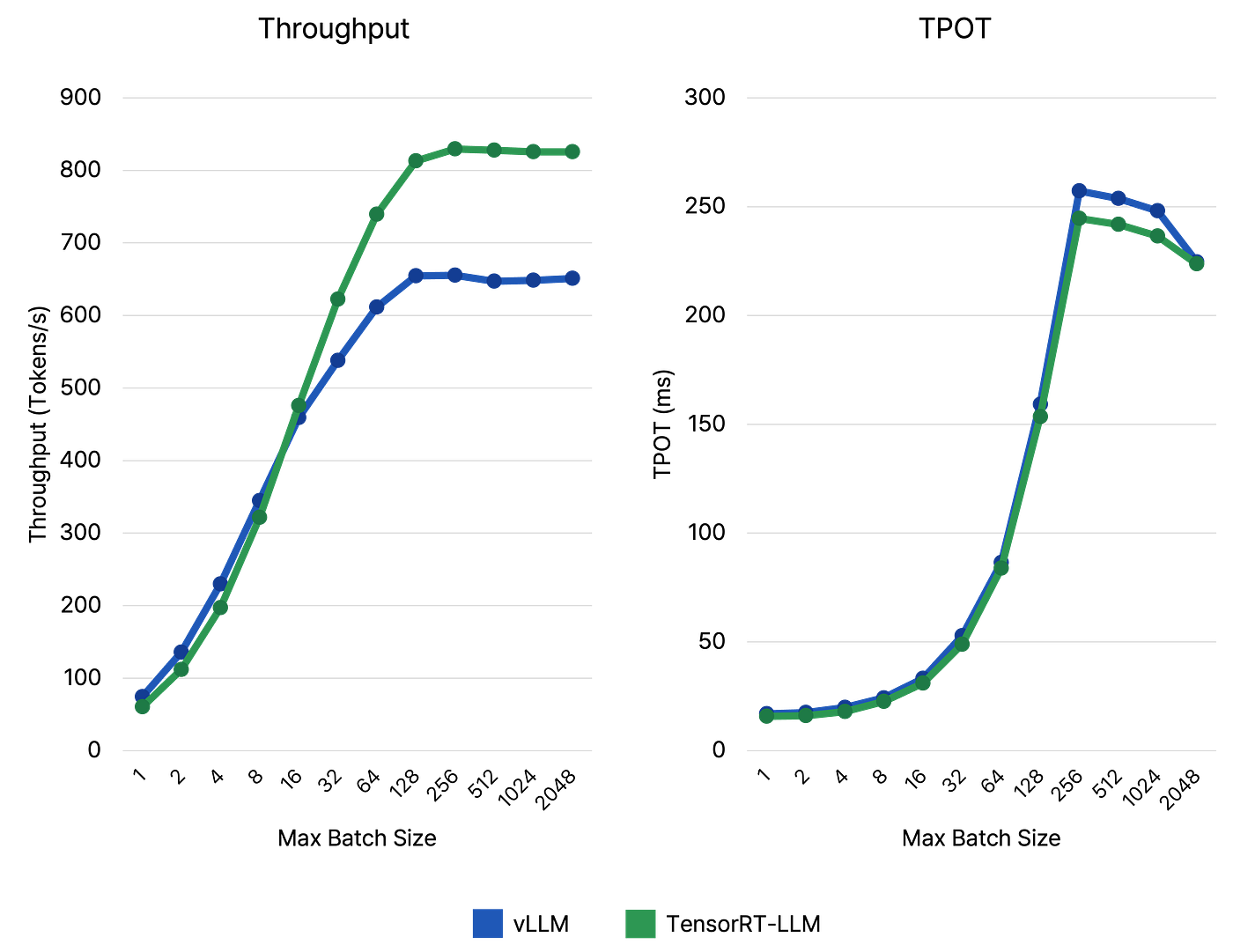
图 3. vLLM 和 TensorRT-LLM 在不同 最大批次大小 选项下的比较。
图 3 显示 TensorRT-LLM 在所有批次大小下,TPOT 均略低于 vLLM。然而,随着最大批次大小的增加,两个框架的吞吐量饱和点显著不同,其中 TensorRT-LLM 的吞吐量明显高于 vLLM。
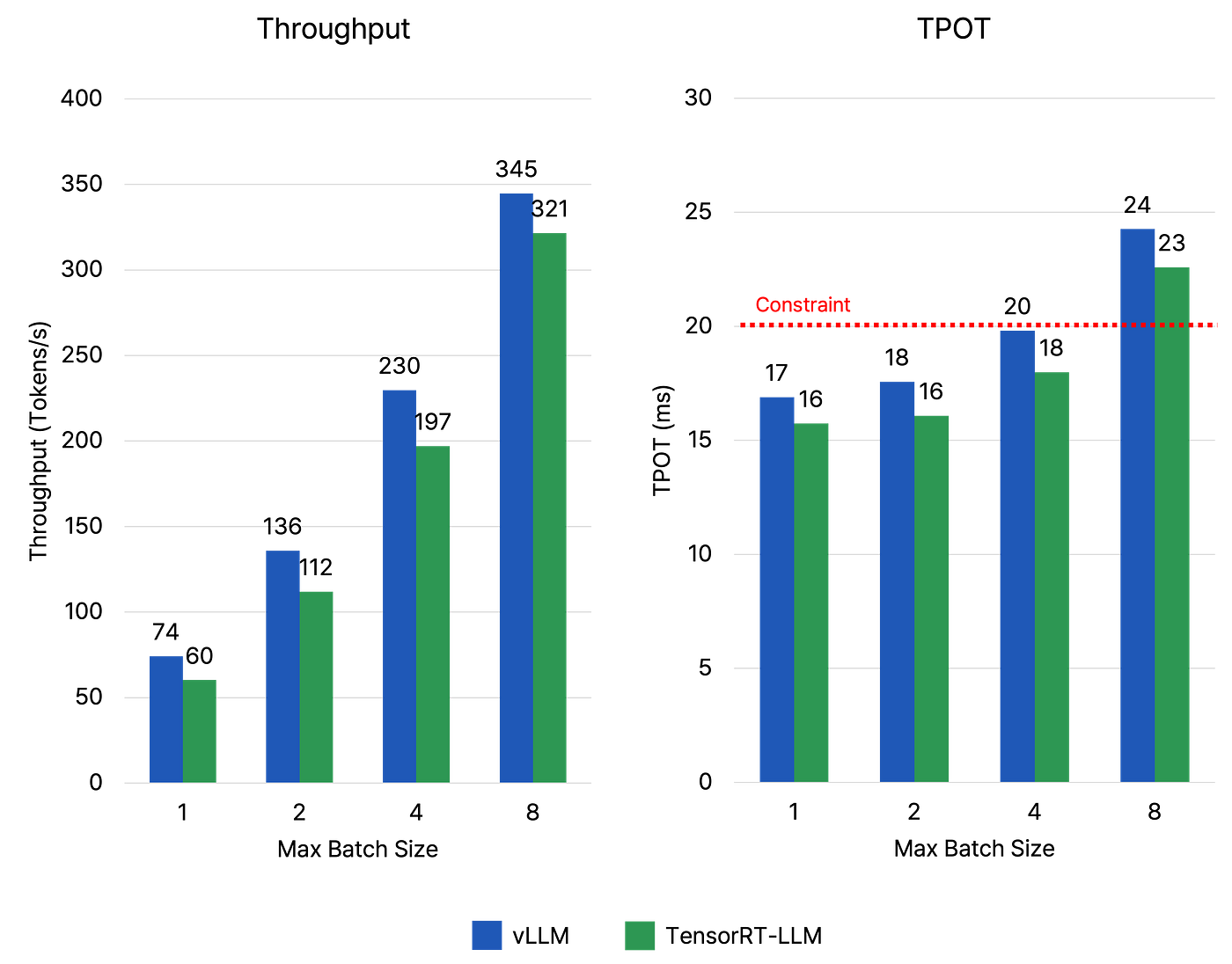
图 4. 在严格 TPOT 约束(20ms)下 vLLM 和 TensorRT-LLM 的比较。此时仅允许使用较小的批次大小。
相反,在施加严格的 20ms TPOT 约束时,吞吐量表现出了不同的趋势,此时只允许较小的批次大小。如 图 4 所示,最大批次大小为 4 是 vLLM 和 TensorRT-LLM 在该约束下的最佳选择。在这种情况下,vLLM 达到了 230 Tokens/s,优于 TensorRT-LLM 的 197 Tokens/s,因此在这一场景中,vLLM 表现更佳。
场景2:TTFT 受限场景
这次,我们假设有一个严格的 TTFT 约束。在实时交互任务中,例如聊天机器人或虚拟助手,用户期望得到即时反馈。较低的 TTFT 确保了快速响应,从而带来自然的对话流,而较高的 TTFT 则会使系统感觉缓慢且响应不及时。在本实验中,我们假设 TTFT 限制为小于 1 秒,目标是实现近乎即时的响应。
• 工作负载:随机数据集包含 512 个样本,固定输入和输出长度为 (2048, 128)
• 要求:TTFT 必须小于 1 秒
• 目标:最大化吞吐量
TTFT 与请求速率
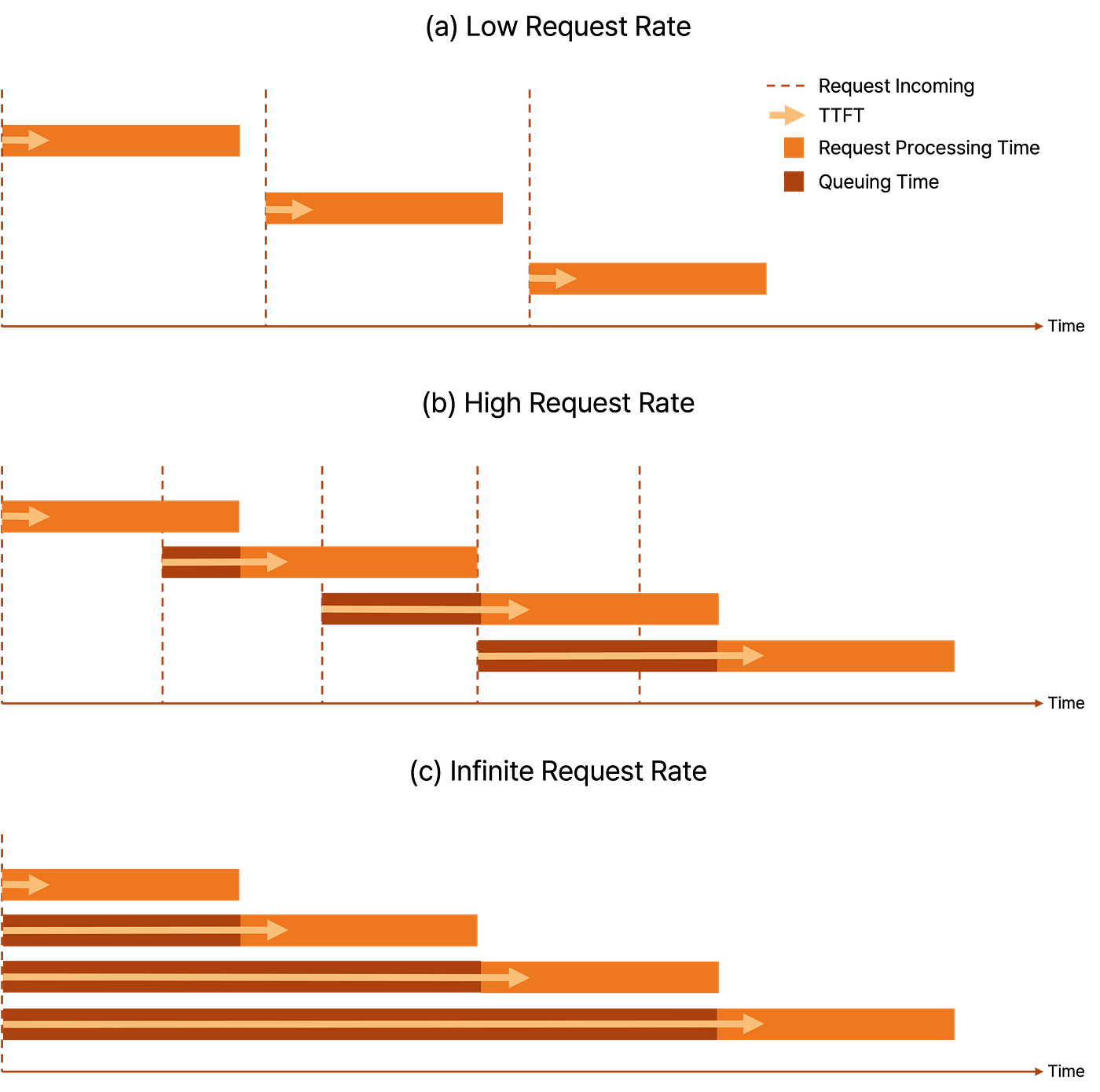
图 5. TTFT 与请求速率的关系
图 5 解释了 TTFT 与 请求速率 之间的密切关系。当请求速率较低时,每个请求在下一个请求到达之前完成,从而避免了排队。因此,TTFT 几乎与预填充阶段的延迟相同。然而,随着 请求速率的增加,处理时间超过了请求到达之间的间隔,从而导致 排队延迟 随着请求数量的增加而增加。
与此同时,vLLM 和 TensorRT-LLM 中的默认请求速率设置为无限,这意味着所有请求在基准测试开始时立即到达(见图 5c)。在这种情况下,后续请求的 TTFT 将极高,正如图 2 中的结果所解释的那样。
在本节中,我们尝试了不同的请求速率,找出在满足 TTFT 约束的情况下每个框架能够处理的最大请求速率。除请求速率外,框架的其他设置与默认配置相同。
结果

图 6. 在不同请求速率选项下 vLLM 和 TensorRT-LLM 的比较。
如 图 6 所示,TensorRT-LLM 在各种请求速率下的 TTFT 始终优于 vLLM。在 1 秒 TTFT 约束下,TensorRT-LLM 能够处理 6 个请求每秒,而 vLLM 则能处理最多 5 个请求每秒。TensorRT-LLM 在 6 个请求每秒时达到了 743.44 Tokens/s,而 vLLM 在 5 个请求每秒时达到了 638.94 Tokens/s。因此,TensorRT-LLM 在相同的 1 秒 TTFT 约束下实现了 16.4% 的吞吐量提升。
这种请求处理能力的差异在具有低 TTFT 要求和高请求速率的场景中可能对服务成本产生重大影响,因为 vLLM 需要额外的 GPU 资源来管理更高的负载,而 TensorRT-LLM 则能以更少的资源完成相同的任务。
最终思考
我们的评估表明,选择 vLLM 还是 TensorRT-LLM 很大程度上取决于具体的应用需求和操作约束。
需要注意的是,本文的实验有一些限制。首先,结果仅来自有限的环境(例如,默认配置或对单个参数的调整)。两种框架都有许多有用的功能,例如分块预填充(chunked prefill)和前缀缓存(prefix caching),它们可以改善所有三个指标。其次,数据集非常简单。所有样本长度相同,生成的输出数量也相同,因此无法充分利用 vLLM 和 TensorRT-LLM 的关键功能——Inflight Batching (also known as continuous batching, which is key feature of both vLLM and TensorRT-LLM。第三,未考虑并行性(如 TP 和 PP),因为所有基准测试都是在单个 A100 卡上完成的。
为了实现高效基准测试,我们使用了 FitsOnChips,一个支持不同框架的精确配置调整的 LLM 基准测试工具包。FitsOnChips 允许对每个配置进行微调并可视化其对性能的影响,从而使基准测试过程更加高效和智能化。如果你对该工具包感兴趣,可以在这里了解更多信息。
在本系列的后续文章中,我们将深入探讨高级优化,探索自定义配置,并评估更多使用场景,以便在不同环境中对这些框架进行更全面的评估。希望这次比较能为实践者提供基础信息,帮助他们在 LLM 部署策略上做出明智的决策。
敬请期待更多 [vLLM vs TensorRT-LLM] 系列 的见解!