这篇博客是一系列关于如何借助纯粹、原生的 PyTorch 技术加速生成式 AI 模型的文章的首篇。我们将分享一系列 PyTorch 最新的性能特性,并通过实例展示如何结合这些特性,从而最大限度地提升 PyTorch 的原生性能。
在 2023 年 PyTorch 开发者大会 上,PyTorch 团队宣布了对 Meta 的 Segment Anything(简称“SAM”)模型的重写。这一改进使得代码的运行速度比原来的版本提高了 8 倍,且没有降低精度,完全基于原生 PyTorch 的优化实现。我们运用了多项新的 PyTorch 特性:
- Torch.compile:一种针对 PyTorch 模型的编译器
- GPU 量化:通过降低运算精度来加速模型
- 缩放点积注意力(SDPA):更高效的内存利用的注意力机制实现方式
- 半结构化(2:4)稀疏性:一种针对 GPU 优化的稀疏内存格式
- 嵌套张量:允许将不同大小的数据,如各种尺寸的图像,整合到单个张量中
- 自定义操作符和 Triton:利用 Triton Python DSL 编写 GPU 操作,并通过自定义操作符注册,轻松地将其融入 PyTorch 的各个组件。
OPTIMIZATIONS
接下来,我们将介绍 SAM 模型优化的过程,包括性能分析、瓶颈识别,以及如何将新功能整合进 PyTorch 解决这些问题。我们还将展示 PyTorch 的一些新特性:torch.compile, SDPA, Triton kernels, Nested Tensor and semi-structured sparsity。本文的各个章节是相互衔接、逐步深入的,最终介绍我们的快速版 SAM,现已在 Github 上提供。我们使用了真实的内核和内存追踪数据,借助完全原生的 PyTorch 工具,并通过 Perfetto UI 对这些数据进行了可视化,以此来阐释每项特性的应用价值。
基线情况
我们的 SAM 基准是 Facebook Research 的未经修改的模型,使用的是 float32 数据类型和批量大小为 1。经过一些初始的预热操作之后,我们可以使用 PyTorch 分析器来查看内核追踪情况:
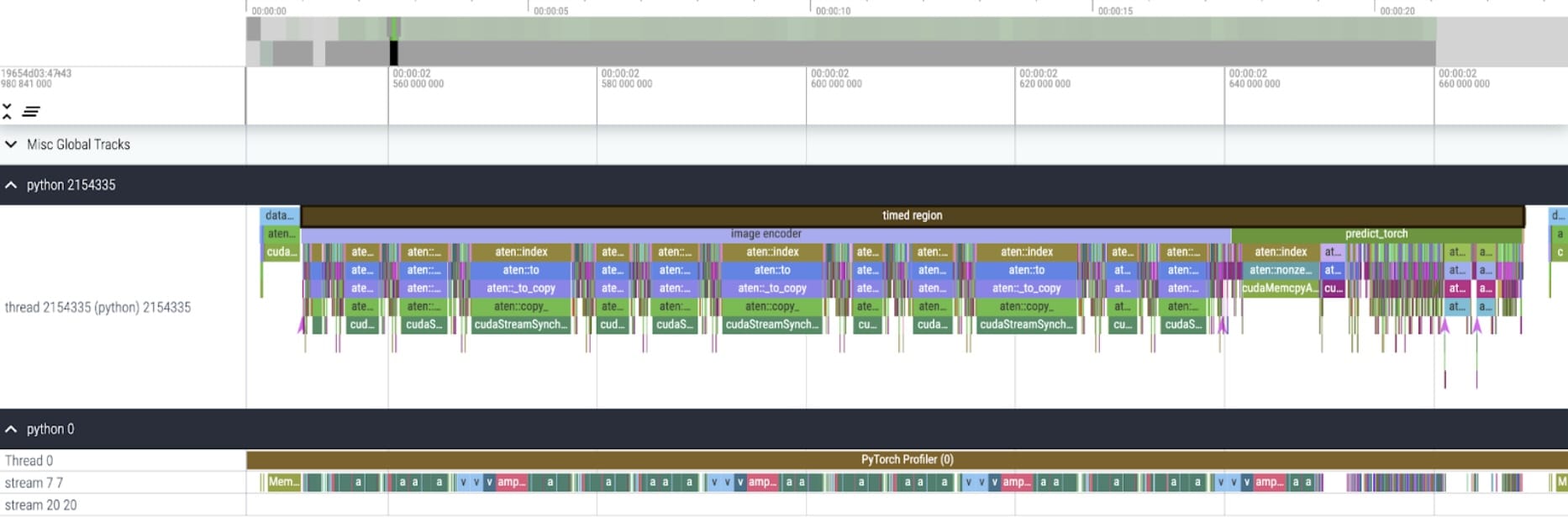
我们发现了两个有待优化的领域。
第一个是频繁的 aten::index 调用,这是由 Tensor 索引操作(例如,)引发的底层调用。虽然实际在 aten::index 上花费的 GPU 时间并不多,但 aten::index 启动了两个内核,并在两者之间发生了阻塞的 cudaStreamSynchronize。这意味着 CPU 需要等待 GPU 完成处理后才能启动第二个内核。为了优化 SAM,我们应该尝试消除这种导致空闲时间的 GPU 同步阻塞。
第二个是在矩阵乘法上花费了大量 GPU 时间(在图中流 7 7 上显示为深绿色)。这在 Transformer 架构中很常见。如果我们能够减少矩阵乘法所占用的 GPU 时间,就可以显著加快 SAM 的速度。
我们可以通过测量 SAM 模型的默认设置下的吞吐量(img/s)和内存开销(GiB)来建立一个基准。
Bfloat16 半精度(加上 GPU 同步和批处理)
为了解决矩阵乘法中耗时较少的问题,我们可以使用 bfloat16。Bfloat16 是一种常用的半精度数据类型。通过降低参数和激活的精度,我们可以显著减少计算过程中的时间和内存消耗。在降低参数精度时,验证模型的端到端准确性非常重要。
用半精度 bfloat16 替换填充数据类型
这里展示了一个例子,即用半精度 bfloat16 替换填充数据类型。相关代码在此。
除了简单地将模型设置为 model.to(torch.bfloat16),我们还需要修改一些假设默认数据类型的地方。
为了消除 GPU 同步,我们需要检查引起它们的操作。我们可以通过搜索 GPU 跟踪记录中的 cudaStreamSynchronize 调用来找到这些代码片段。实际上,我们找到了两个可以重写为无同步的位置。
代码示例 1
用半精度 bfloat16 替换填充数据类型
具体来说,在 SAM 的图像编码器中,有作为坐标缩放器的变量 q_coords 和 k_coords。这些变量都在 CPU 上分配和处理。然而,当这些变量用于 rel_pos_resized 的索引操作时,索引操作会自动将这些变量移至 GPU。这种复制过程导致了我们之前观察到的 GPU 同步。我们在 SAM 的提示编码器中注意到了第二次索引调用:我们可以使用 torch.where 重写这部分,如上所示。
内核追踪
在应用了这些更改之后,我们开始注意到个别内核调用之间有显著的时间间隔。这通常在小批量(这里为 1)时观察到,因为启动内核的 GPU 开销。为了更深入了解实际的优化领域,我们开始对批量大小为 8 的 SAM 推理进行性能分析:
在分析每个内核的耗时时,我们发现 SAM 的大部分 GPU 时间都用于逐元素内核和 softmax 操作。因此,我们现在看到矩阵乘法的相对开销已经大大减小。
矩阵乘法的相对开销已经大大减小
通过结合 GPU 同步和 bfloat16 优化,我们已经将 SAM 的性能提升了高达 3 倍。
SAM 的性能提升了高达 3 倍
Torch.compile(加上图断裂和 CUDA 图)
当观察到大量小型操作,比如上文分析的逐元素内核时,使用编译器来融合操作可以带来显著的好处。PyTorch 最近推出的 torch.compile 在优化方面表现出色,主要通过以下方式:
将例如 nn.LayerNorm 或 nn.GELU 等操作序列融合成一个单一的 GPU 内核,然后进行调用
尾声:融合紧跟在矩阵乘法内核之后的操作,以减少 GPU 内核调用的次数。
通过这些优化,我们减少了 GPU 全局内存往返的次数,从而加速了推理过程。现在我们可以尝试在 SAM 的图像编码器上使用 torch.compile。为了最大化性能,我们采用了一些高级编译技巧,例如:
使用 torch.compile 的最大自动调优模式,启用了 CUDA 图和针对特定形状的内核,带有自定义尾声。
通过设置 TORCH_LOGS=“graph_breaks,recompiles”,我们可以手动确认我们没有遇到图断裂或重新编译的情况。
通过用零填充编码器的图像批次,确保 compile 接受静态形状,从而始终使用针对特定形状的优化内核,带有自定义尾声,无需重新编译。