回顾 Flashattention
FlashAttention重排了Attention的计算,并利用tiling、recompute来显著加快速度并将内存使用量从二次降低到线性。tiling意味着我们从HBM(GPU内存)加载输入块到SRAM(快速缓存),对该块进行注意力计算,并在HBM中更新输出。由于不将大型中间注意力矩阵写入HBM,减少了内存读/写的数量,从而带来2-4倍的加速。
With tiling and softmax rescaling, we operate by blocks and avoid having to read/write from HBM, while obtaining the correct output with no approximation.

然而,由于在GPU上不同线程块和warp之间的工作划分不够优化,FlashAttention仍然存在一些低效问题,导致低占用率或不必要的共享内存读写。
FlashAttention 2
FlashAttention 2 在 FlashAttention 的基础上进行了进一步的性能优化,其计算结果仍然是严格对齐的。
Better Algorithm, Parallelism, and Work Partitioning
Fewer non-matmul FLOPs
可以理解为多利用Tensor Core
我们优化了FlashAttention的算法,减少了非矩阵乘法浮点运算。这很重要,因为现代GPU有专门的计算单元(例如,Nvidia GPU上的Tensor Cores)使得矩阵乘法运算更快。例如,A100 GPU最大理论吞吐量为312 TFLOPs/s的FP16/BF16矩阵乘法,但非矩阵乘法FP32只有19.5 TFLOPs/s。也可以理解为每个非矩阵乘法浮点运算是矩阵乘法浮点运算的16倍。为了保持高吞吐量,我们希望尽可能多地进行矩阵乘法运算。
重写了FlashAttention中使用的在线softmax技巧,减少了rescaling ops数量,同时在不改变输出的情况下减少了边界检查和causal masking operations。
Better Parallelism
The first version of FlashAttention parallelizes over batch size and number of heads. We use 1 thread block to process one attention head, and there are overall (batch_size * number of heads) thread blocks. Each thread block is scheduled to run on a streaming multiprocessor (SM), and there are 108 of these SMs on an A100 GPU for example. This scheduling is efficient when this number is large (say >= 80), since we can effectively use almost all of the compute resources on the GPU.
In the case of long sequences (which usually means small batch sizes or small number of heads), to make better use of the multiprocessors on the GPU, we now additionally parallelize over the sequence length dimension. This results in significant speedup for this regime.
Better Work Partitioning
Even within each thread block, we also have to decide how to partition the work between different warps (a group of 32 threads working together). We typically use 4 or 8 warps per thread block, and the partitioning scheme is described below. We improve this partitioning in FlashAttention-2 to reduce the amount of synchronization and communication between different warps, resulting in less shared memory reads/writes.
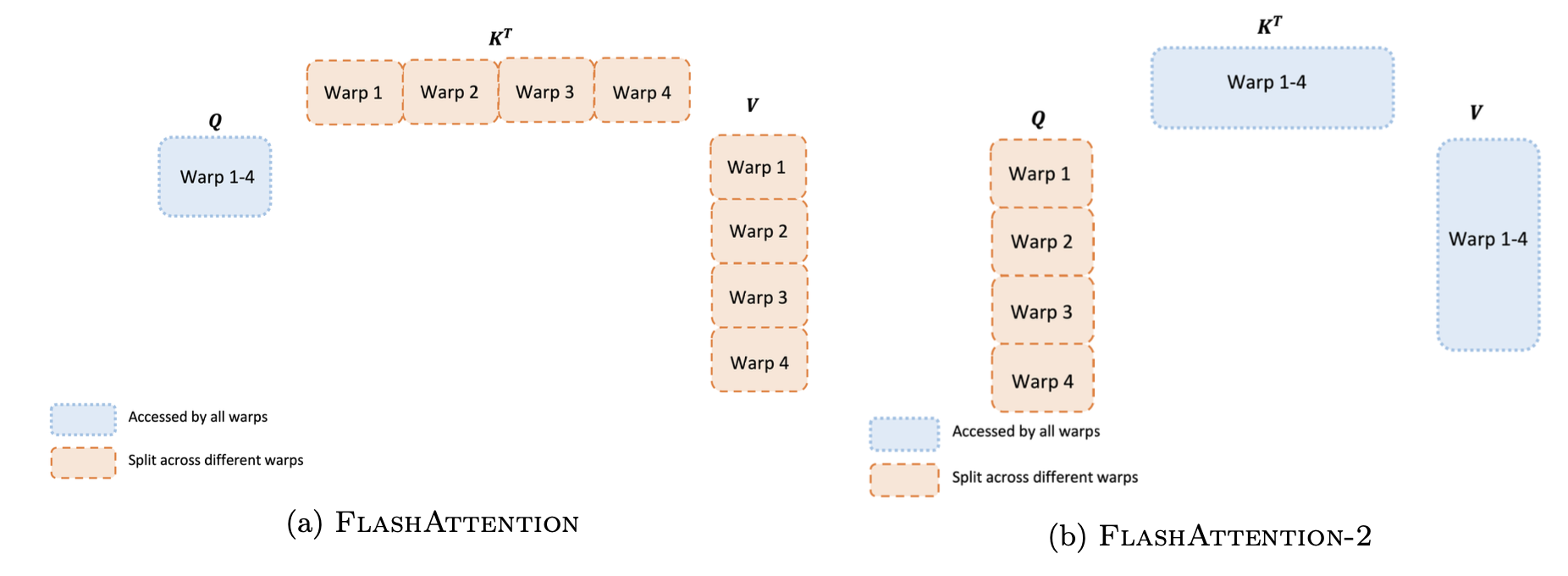
For each block, FlashAttention splits K and V across 4 warps while keeping Q accessible by all warps. This is referred to as the “sliced-K” scheme. However, this is inefficient since all warps need to write their intermediate results out to shared memory, synchronize, then add up the intermediate results. These shared memory reads/writes slow down the forward pass in FlashAttention.
In FlashAttention-2, we instead split Q across 4 warps while keeping K and V accessible by all warps. After each warp performs matrix multiply to get a slice of Q K^T, they just need to multiply with the shared slice of V to get their corresponding slice of the output. There is no need for communication between warps. The reduction in shared memory reads/writes yields speedup
New features: head dimensions up to 256, multi-query attention
FlashAttention only supported head dimensions up to 128, which works for most models but a few were left out. FlashAttention-2 now supports head dimension up to 256, which means that models such as GPT-J, CodeGen and CodeGen2, and StableDiffusion 1.x can use FlashAttention-2 to get speedup and memory saving.
This new version also supports multi-query attention (MQA) as well as grouped-query attention (GQA). These are variants of attention where multiple heads of query attend to the same head of key and value, in order to reduce the size of KV cache during inference and can lead to significantly higher inference throughput.
