功能
功能方面尤为重要的是以下两点:
- 支持的模型的多寡,这个不必多说
- 支持模型量化方式的多样,这个功能允许用户牺牲一定的模型准确率,换取更快的生成速度,更长的上下文,在计算资源不充足的时候非常有效。
此外还有一些功能在特定场景下很重要,比如多 lora 支持可以在用户需要同时使用多个同源微调模型时大大提升效率;guided decoding 可以按用户规定的格式生成结构化输出。
性能
当我们讨论性能时,从用户视角来看,我们在意的是用户体验,因此通常考虑以下几个指标:
- TTFT(time to first token):,首 token 耗时
- TPOT(time per output token):首 token 后,每个 token 间的耗时
- 总延迟:处理一个用户请求的总耗时,即 TTFT + TPOT*(生成 token 数 - 1)
作为用户,我们希望尽快得到生成的结果,因此上面三个指标越小越好。
然而从系统角度看,更在意的是下面这个指标:
- 吞吐(throughput):单位时间生成的 token 数量。
- 好吞吐(goodput):满足一定 TTFT 与 TPOT 约束情况下,单位时间生成的 token 数量。
吞吐是一个常见的指标,下面解释以下什么是好吞吐。
举个例子,在对话场景下,通常我们希望在 1 秒内得到 ChatGPT 的相应(即 TTFT <= 1s),而后以略快于人类阅读速度的速度(即 TPOT <=150 ms)收到对话内容。然而在负载较大的时候,有一些请求无法满足上面的约束,goodput 便是指排除这些请求后的 throughput。换句话说,就是在满足用户场景对延迟的要求下,尽可能的提高吞吐。
我们可以用下面这张图把用户视角和系统视角在意的数据串起来:
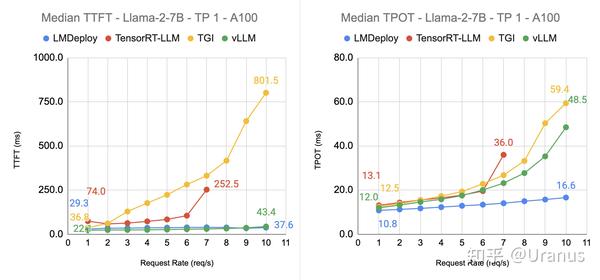
上图中,y 轴分别表示 TTFT 和 TPOT 的中位数,x 轴则表示请求频率(类似 QPS),一个好的推理引擎应该做到如图中 LMDeploy 一样,随着请求频率增加,TTFT 和 TPOT 的中位数几乎不变,这意味着引擎的处理能力大大高于当前的请求频率
这里总结LLM高性能推理加速相关技术,包括几个方面:
- 计算图和OP优化
- 推理框架
- LLM结构运行时系统架构
计算图和OP优化
- KV Cache
- GQA、MQA
- FlashAttention v1 、v2
- FlashDecoding
PageAttention
推理库
大模型推理——FasterTransformer + TRITON
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
LLMs承诺彻底改变我们在所有行业中使用人工智能的方式。然而,实际上为这些模型提供服务是具有挑战性的,即使在昂贵的硬件上也可能非常缓慢。今天,我们很高兴介绍vLLM,这是一个用于快速LLM推理和服务的开源库。vLLM利用了PagedAttention,我们新的注意力算法,有效地管理注意力键和值。配备PagedAttention的vLLM重新定义了LLM服务领域中最先进技术:它提供比HuggingFace Transformers高达24倍的吞吐量,而无需进行任何模型架构更改。
vLLM已经在加州大学伯克利分校开发,并在Chatbot Arena和Vicuna Demo部署了过去两个月。它是使得即使对于像LMSYS这样计算资源有限的小型研究团队来说也可以负担得起LLM服务核心技术。现在,在我们GitHub存储库中只需一个命令就可以尝试使用vLLM。
lmdeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features:
- Efficient Inference Engine (TurboMind): Based on FasterTransformer, we have implemented an efficient inference engine - TurboMind, which supports the inference of LLaMA and its variant models on NVIDIA GPUs.
- Interactive Inference Mode: By caching the k/v of attention during multi-round dialogue processes, it remembers dialogue history, thus avoiding repetitive processing of historical sessions.
- Multi-GPU Model Deployment and Quantization: We provide comprehensive model deployment and quantification support, and have been validated at different scales.
- Persistent Batch Inference: Further optimization of model execution efficiency.
4-bit Inference
This release adds efficient inference routines for batch size 1. Expected speedups vs 16-bit precision (fp16/bf16) for matrix multiplications with inner product dimension of at least 4096 (LLaMA 7B) is:
- 2.2x for Turing (T4, RTX 2080, etc.)
- 3.4x for Ampere (A100, A40, RTX 3090, etc.)
- 4.0x for Ada/Hopper (H100, L40, RTX 4090, etc.)
The inference kernels for batch size 1 are about 8x faster than 4-bit training kernel for QLoRA. This means you can take advantage the new kernels by separating a multi-batch 4-bit query into multiple requests with batch size 1.
No code changes are needed to take advantage of the new kernels as long as a batch size of 1 is used.
Big thanks to @crowsonkb, @Birch-san, and @sekstini for some beta testing and helping to debug some early errors.
LLM结构运行时推理框架
continuous batching
in-flight batching
- Speculative Decoding https://zhuanlan.zhihu.com/p/677142291
投机推理
- EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test